秒杀技术挑战
对现有网站业务造成冲击
将秒杀系统独立部署,甚至使用独立域名,使其与网站完全隔离。
高并发下的应用、数据库负载
重新设计秒杀商品页面,不使用网站原来的商品详细页面,页面内容静态话,用户请求不需要经过应用服务。
突然增加的网络及服务器带宽
因为秒杀新增的网络带宽,必须和运营商重新购买或者租借。为了减轻网站服务器的压力,需要将秒杀商品页面缓存在CDN,同样需要和CDN服务商临时租借新增的出口带宽。
直接下单
下单页面也是一个普通的URL,如果得到这个URL,不用等到秒杀开始就可以下单了。
需要将该URL动态化,即使秒杀系统的开发者也无法在秒杀开始前访问下单页面的URL。方法是在下单页面URL加入由服务器端生成的随机数作为参数,在秒杀开始的时候才能得到。
如果控制秒杀商品页面购买按钮的点亮
在秒杀商品静态页面中加入一个JavaScript文件引用,该JavaScript文件中包含秒杀开始与否标志。这个JavaScript文件非常小,即使每次浏览器刷新都访问JavaScript文件服务器,也不会对服务器集群和网络带宽造成太大压力。
如果只允许第一个提交的订单被发送到订单子系统
假设下单服务器集群有10台服务器,每台服务器只接受最多10个下单请求。
在还没有人提交订单成功之前,如果一个服务器已经有10单了,而有的一单都没处理,可能出现的用户体验不佳的场景是用户第一次点击购买按钮进入已结束页面,再刷新一下页面,有可能被一单都没有处理的服务器处理,进入了填写订单的页面,可以考虑通过cookie的方式来应对,符合一致性原则。当然可以采用最少连接的负载均衡算法,出现上述情况的概率大大降低。
如何进行下单前置检查
- 下单服务器检查本机已处理的下单请求数目
如果超过10条,直接返回已结束页面给用户
如果未超过10条,则用户可进入填写订单及确认页面
- 检查全局已提交订单数目
已超过秒杀商品总数,返回已结束页面给用户
未超过秒杀商品总数,提交到子订单系统
秒杀一般是定时上架
减库存的操作
有两种选择,一种是拍下减库存;另一种是付款减库存
库存会带来‘超卖’的问题
采用乐观锁
UPDATE auction_auctions SET
quantity = #inQuantity#
WHERE auction_id = #itemId# and quantity = #dbQuantity#
秒杀器的应对
秒杀器一般下单购买及其迅速,根据购买记录可以甄别出一部分。可以通过校验码达到一定的方法。
秒杀架构原则
尽量将请求拦截在系统上游
读多写少的多使用缓存
秒杀架构设计
- 秒杀系统的页面设计尽可能简单
- 购买按钮只有在秒杀活动开始的时候才变亮
- 下单表单也尽可能简单;只有第一个提交的订单发送给网站的订单子系统,其余用户提交订单后只能看到秒杀结束页面
前端层设计
秒杀页面的展示
各类静态资源首先应分开存放,然后放到CDN节点上分散压力
倒计时
可能出现客户端时钟与服务器时钟不一致,另外服务器之间也是有可能出现时钟不一致。
浏览器层请求拦截
- 产品层面:用户点击后,按钮置灰
- JS层面:限制用户在x秒之内只能提交一次请求
站点层设计
- 同一个uid,限制访问频率:做页面缓存,x秒内到达站点层的请求,均返回同一个页面
- 同一个item的查询,均返回同一个页面
服务层设计
并发队列的选择
- ArrayBlockingQueue是初始容量固定的阻塞队列,我们可以用来作为数据库模块成功竞拍的队列。比如有10个商品,那么我们就设定一个大小为10的数组队列。
- ConcurrentLinkedQueue使用的是CAS无锁队列,是一个异步队列,入队的速度很快,出队进行了加锁,性能稍慢。
- LinkedBlockingQueue也是阻塞的队列,入队和出队都加了锁,当队空的时候线程会暂时阻塞。
由于我们的系统入队需求要远大于出队需求,一般不会出现队空的情况,所以我们可以选择ConcurrentLinkedQueue来作为我们的请求队列实现。
数据库模块数据库主要是使用一个ArrayBlockingQueue来暂存有可能成功的用户请求。
数据库设计
设计思路
如何保证数据的可用性?
冗余。
如何保证数据库‘读’高可用?
冗余读库
如何保证数据库‘写’高可用?
冗余写库。采用双主互备的方式。
双写同步,数据可能冲突(例如‘自增id’同步冲突),有两种常见解决方案:
- 两个写库使用不同的初始值,相同的步长来增加id:写库1的id为0,2,,4,6……;写库2的id为1,3,5,7……
- 不使用数据的id,业务层自己生成唯一的id。保证数据不冲突。
如何扩展读性能
- 第一种是建立索引:不同的库可以建立不同的索引 - 线上读库建立线上访问索引,例如uid - 线下读库建立线下访问索引,例如time
- 第二种是增加从库
- 第三种是增加缓存
如何保证一致性
主从数据库的一致性,通常有两种解决方案:
- 中间件:如果某一个key有写操作,在不一致时间窗口内,中间件会将这个key的读操作也路由到主库上。
- 强制读主
DB与缓存间的不一致:有可能“从库读到旧数据,旧数据进入cache”
写操作时顺序升级为:
- 淘汰cache
- 写数据库
- 在经验‘主从同步延时窗口时间’达到了以后,再次发起一个异步淘汰cache的请求。
作弊的手段:
同一个帐号,一次性发出多个请求
在程序入口处,一个帐号只允许接受1个请求,其他请求过滤。
可以通过Redis这种内存缓存服务,写入一个标志位(只允许1个请求写成功),成功写入的则可以继续参加。
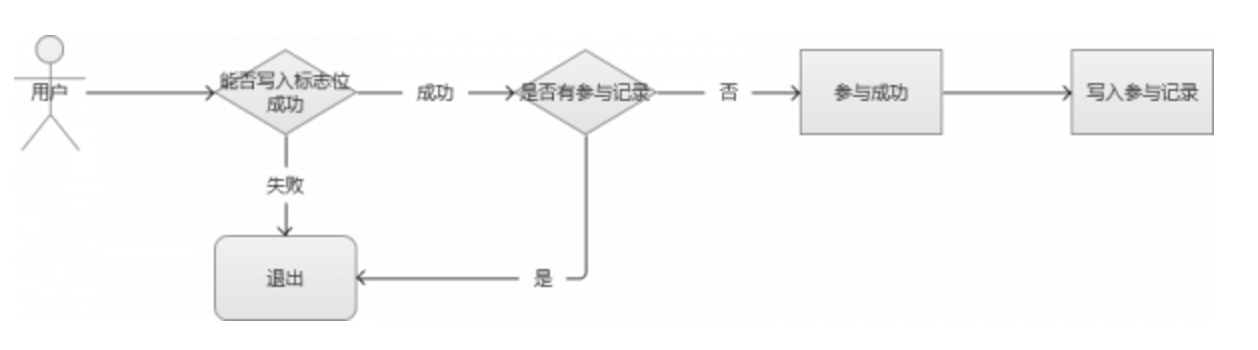
或者自己实现一个服务,将同一个帐号的请求放入一个队列中,处理完一个,再处理下一个。
多个帐号,一次性发送多个请求
可以通过检测机器IP请求频率
- 弹出验证码
- 直接禁止IP
多个帐号,不同IP发送不同请求
通过帐号行为的‘数据挖掘’来提前清理掉它们。
高并发下的数据安全
悲观锁思路
在修改数据的时候,采用锁定状态,排斥外部请求的修改。遇到加锁的状态,就必须等待。
FIFO队列思路
强行将多线程变成单线程。
我们直接将请求放入队列中,采用FIFO。
乐观锁思路
这个数据的所有请求都有资格去修改,但是会获得一个该数据的版本号,只有版本号符合的才能更新成功,其他的返回抢购失败。